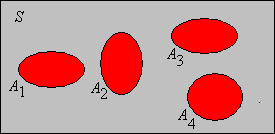
This section contains the final and most important ingredient in the basic model of a random experiment. Essential prerequisites for this section are set theory, functions, cardinality (in particular, the distinction between countableand uncountable sets), and counting measure. Measure spaces also playa a fundamental role, but if you are a new student of probability, just ignore the measure-theoretic terminology and skip the technical details.
Suppose that we have a random experiment with sample space \( (S, \ms S) \) so that \( S \) is the set of outcomes of the experiment and \( \ms S \) is the collection of events. When we run the experiment, a given event \( A \) either occurs or does not occur, depending on whether the outcome of the experiment is in \( A \) or not. Intuitively, the probability of an event is a measure of how likely the event is to occur when we run the experiment. Mathematically, probability is a function on the collection of events that satisfies certain axioms.
A probability measure (or probability distribution) \(\P\) on the sample space \( (S, \ms S) \) is a real-valued function defined on \( \ms S \) that satisifes the following axioms:
Recall that the collection of events \( \ms S \) is required to be a \( \sigma \)-algebra, which guarantees that the union of the events in part (c) of is itself an event. A probability measure is a special case of a positive measure. Axiom (c) is known as countable additivity, and states that the probability of a union of a finite or countably infinite collection of disjoint events is the sum of the corresponding probabilities. The axioms are known as the Kolmogorov axioms, in honor of Andrei Kolmogorov who was the first to formalize probability theory in an axiomatic way. More informally, we say that \( \P \) is a probability measure (or distribution) on \( S \), the collection of events \( \ms S \) usually being understood.
Axioms (a) and (b) are really just a matter of convention; we choose to measure the probability of an event with a number between 0 and 1 (as opposed, say, to a number between \(-5\) and \(7\)). Axiom (c) however, is fundamental and inescapable. It is required for probability for precisely the same reason that it is required for other measures of the size
of a set, such as cardinality for finite sets, length for subsets of \(\R\), area for subsets of \(\R^2\), and volume for subsets of \(\R^3\). In all these cases, the size of a set that is composed of countably many disjoint pieces is the sum of the sizes of the pieces.
On the other hand, uncountable additivity (the extension of axiom (c) to an uncountable index set \(I\)) is unreasonable for probability, just as it is for other measures. For example, an interval of positive length in \(\R\) is a union of uncountably many points, each of which has length 0.
We now have defined the three essential ingredients for the model a random experiment:
A probability space \( (S, \ms S, \P) \) consists of
The sample space \( (S, \ms S) \) is a measurable space and the probability space \( (S, \ms S, \P) \) is a special case of a positive measure space. So in a strict sense, probability theory is a special case of measure theory. But that statement is misleading because probability theory has its own language, concepts, and applications far removed from other areas of measure theory.
Intuitively, the probability of an event is supposed to measure the long-term relative frequency of the event—in fact, this concept was taken as the definition of probability by Richard Von Mises. Here are the relevant definitions:
Suppose that the experiment is repeated indefinitely, and that \( A \) is an event. For \( n \in \N_+ \),
Note that repeating the original experiment indefinitely creates a new, compound experiment, and that \( N_n(A) \) and \( P_n(A) \) are random variables for the new experiment. In particular, the values of these variables are uncertain until the experiment is run \( n \) times. The basic idea is that if we have chosen the correct probability measure for the experiment, then in some sense we expect that the relative frequency of an event should converge to the probability of the event. That is, \[P_n(A) \to \P(A) \text{ as } n \to \infty, \quad A \in \ms S\] regardless of the uncertainty of the relative frequencies on the left. The precise statement of this is the law of large numbers or law of averages, one of the fundamental theorems in probability. To emphasize the point, note that in general there will be lots of possible probability measures for an experiment, in the sense of the axioms in . However, only the probability measure that models the experiment correctly will satisfy the law of large numbers.
Given the data from \( n \) runs of the experiment, the empirical probability function \(P_n\) is a probability measure on \( (S, \ms S) \).
If we run the experiment \( n \) times, we generate \( n \) points in \( S \) (although of course, some of these points may be the same). The function \( A \mapsto N_n(A) \) for \( A \subseteq S \) is simply counting measure on \((S, \ms S)\) corresponding to the \( n \) points. Clearly \( P_n(A) \ge 0 \) for an event \( A \) and \( P_n(S) = n / n = 1 \). Countable additivity holds by the addition rule for counting measure.
Suppose now that \((T, \ms T)\) is another measurable space and that \(X\) is a random variable for the experiment with values in set \(T\). Recall that mathematically, \( X \) is a measurable function from \( S \) into \( T \), and \( \{X \in A\}\) denotes the event \(\{s \in S: X(s) \in A\} \) for \( A \in \ms T \). Intuitively, \( X \) is a variable of interest for the experiment, and every meaningful statement about \( X \) defines an event.
The function \(A \mapsto \P(X \in A)\) for \( A \in \ms T \) defines a probability measure on \((T, \ms T)\).
The proof is simple because inverse images preserve all of the set operations.
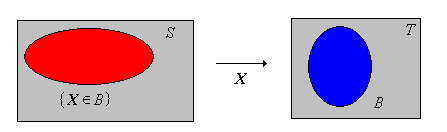
This probability measure is called the probability distribution of \(X\), so we have all of the ingredients for a new probability space.
A random variable \(X\) with values in \( T \) as above defines a new probability space:
This probability space corresponds to the new random experiment in which the outcome is \( X \). Moreover, recall that the outcome of the experiment itself can be thought of as a random variable. Specifically, if we let \(T = S\), \(\ms T = \ms S\), and let \(X\) be the identity function on \(S\), so that \( X(s) = s \) for \( s \in S \). Then \(X\) is a random variable with values in \( S \) and \(\P(X \in A) = \P(A)\) for each \( A \in \ms S \). So every probability measure can be thought of as the distribution of a random variable.
How can we construct probability measures? As noted briefly above, there are other measures of the size
of sets; in many cases, these can be converted into probability measures. First, a positive measure \(\mu\) on the sample space \((S, \ms S)\) is a real-valued function defined on \(\ms S\) that satisfies axioms (a) and (c) in , and then \( (S, \ms S, \mu) \) is a measure space. In general, \(\mu(A)\) is allowed to be infinite. However, if \(\mu(S)\) is positive and finite (so that \( \mu \) is a finite positive measure), then \(\mu\) can easily be re-scaled into a probability measure.
If \(\mu\) is a positive measure on \(S\) with \(0 \lt \mu(S) \lt \infty\) then \(\P\) defined below is a probability measure on \((S, \ms S)\) \[\P(A) = \frac{\mu(A)}{\mu(S)}, \quad A \in \ms S\]
In this context, \(\mu(S)\) is called the normalizing constant. In the next two subsections, we consider some very important special cases.
In this discussion, we assume that the sample space \((S, \ms S)\) is discrete. Recall that this means that the set of outcomes \(S\) is countable and that \(\ms S = \mathscr P(S)\) is the collection of all subsets of \(S\), so that every subset is an event. The standard measure on a discrete space is counting measure \(\#\), so that \(\#(A)\) is the number of elements in \(A\) for \(A \subseteq S\). When \( S \) is finite, the probability measure corresponding to counting measure, as constructed in , is particularly important in combinatorial and sampling experiments.
Suppose that \(S\) is a finite, nonempty set. The discrete uniform distribution on \(S\) is given by \[\P(A) = \frac{\#(A)}{\#(S)}, \quad A \subseteq S\]
The underlying model is refereed to as the classical probability model, because historically the very first problems in probability (involving coins and dice) fit this model.
In the general discrete case, if \(\P\) is a probability measure on \(S\), then since \( S \) is countable, it follows from countable additivity that \(\P\) is completely determined by its values on the singleton events. Specifically, if we define \(f(x) = \P\left(\{x\}\right)\) for \(x \in S\), then \(\P(A) = \sum_{x \in A} f(x)\) for every \(A \subseteq S\). By axiom (a), \(f(x) \ge 0\) for \(x \in S\) and by axiom (b), \(\sum_{x \in S} f(x) = 1\). Conversely, we can give a general construction for defining a probability measure on a discrete space.
Suppose that \( g: S \to [0, \infty) \). Then \(\mu\) defined by \( \mu(A) = \sum_{x \in A} g(x) \) for \( A \subseteq S \) is a positive measure on \(S\). If \(0 \lt \mu(S) \lt \infty\) then \(\P\) defined as follows is a probability measure on \(S\). \[ \P(A) = \frac{\mu(A)}{\mu(S)} = \frac{\sum_{x \in A} g(x)}{\sum_{x \in S} g(x)}, \quad A \subseteq S\]
Trivially \(\mu(A) \ge 0\) for \( A \subseteq S \) since \(g\) is nonnegative. The countable additivity property holds since the terms in a sum of nonnegative numbers can be rearranged in any way without altering the sum. Thus let \(\{A_i: i \in I\}\) be a countable collection of disjoint subsets of \( S \), and let \(A = \bigcup_{i \in I} A_i\) then \[ \mu(A) = \sum_{x \in A} g(x) = \sum_{i \in I} \sum_{x \in A_i} g(x) = \sum_{i \in I} \mu(A_i) \] If \( 0 \lt \mu(S) \lt \infty \) then \( \P \) is a probability measure by .
In the context of our previous remarks, \(f(x) = g(x) \big/ \mu(S) = g(x) \big/ \sum_{y \in S} g(y)\) for \( x \in S \). Distributions of this type are said to be discrete.
If \(S\) is finite and \(g\) is a constant function, then the probability measure \(\P\) associated with \( g \) is the discrete uniform distribution on \(S\).
Suppose that \(g(x) = c\) for \(x \in S\) where \(c \gt 0\). Then \(\mu(A) = c \#(A) \) and hence \(\P(A) = \mu(A) \big/ \mu(S) = \#(A) \big/ \#(S)\) for \( A \subseteq S \).
For \(n \in \N_+\), the \(n\)-dimensional Euclidean measure space is \((\R^n, \ms R^n, \lambda^n)\) where \(\ms R^n\) is the Borel \(\sigma\)-algebra of subsets of \(\R^n\) and \(\lambda^n\) is Lebesgue measure. When \(n = 1\) we drop the superscripts. Recall that \(\ms R\) is generated by intervals, and more generally, \(\ms R^n\) is generated by Cartesian products of \(n\)-intervals for \(n \in \N_+\). Recall also that \(\lambda\) is length on sets in \(\ms R\), \(\lambda^2\) is area on sets in \(\ms R^2\), \(\lambda^3\) is volume on sets in \(\ms R^3\), and generally \(\lambda^n\) is \(n\)-dimensional volumen on sets in \(\ms R^n\). The integral of a measurable function \(f: \R^n \to \R\) over a set \(A \in \ms R^n\) with respect to \(\lambda^n\) (the Lebesgue integral) is denoted \[\int_A f(x) \, dx\] As the notation indicates, the Lebesgue integral agrees with the ordinary Riemann integral of calculus when \(f\) and \(A\) are sufficiently nice. Note that if \(n \gt 1\) then this integral is a multiple integral. Suppose now that our sample space \((S, \ms S)\) is a subspace of a Euclidean space so that \(S \in \ms R^n\) for some \(n \in \N_+\) and \(\ms S = \{A \in \ms R^n: A \subseteq S\}\). The probability measure constructed in is particularly important:
Suppose that \(0 \lt \lambda^n(S) \lt \infty\). The continuous uniform distribution on \( S \) is defined by \[\P(A) = \frac{\lambda^n(A)}{\lambda^n(S)}, \quad A \in \ms S\]
Note that the continuous uniform distribution is analogous to the discrete uniform distribution in , but with Lebesgue measure \( \lambda^n \) replacing counting measure \( \# \). We can generalize this construction to produce many other distributions.
Suppose that \( g: S \to [0, \infty) \) is measurable. Then \( \mu \) defined by \( \mu(A) = \int_A g(x) \, dx \) for \( A \in \ms S \) is a positive measure on \( (S, \ms S) \). If \(0 \lt \mu(S) \lt \infty\), then \( \P \) defined as follows is a probability measure on \( (S, \ms S) \). \[\P(A) = \frac{\mu(A)}{\mu(S)} = \frac{\int_A g(x) \, dx}{\int_S g(x) \, dx}, \quad A \in \ms S\]
The function \(g\) is the density function of \(\mu\) with respect to \(\lambda^n\). Technicalities aside, the proof is straightforward using properties of the integral
If \( 0 \lt \mu(S) \lt \infty \) then \( \P \) is a probability measure on \( S \) by .
Distributions of this type are said to be continuous because \(P\{x\} = 0\) for \(x \in S\). Note that the continuous distribution above is analogous to the discrete distribution in , but with integrals replacing sums. The general theory of integration allows us to unify these two special cases, and many others besides.
Suppose again that we have a random experiment modeled by a probability space \( (S, \ms S, \P) \), so that \(S\) is the set of outcomes, \( \ms S \) is the collection of events, and \( \P \) is the probability measure on the sample space \((S, \ms S)\). In the following theorems, \(A\) and \(B\) are events. The results follow easily from the axioms of probability in , so be sure to try the proofs yourself before expanding the details.
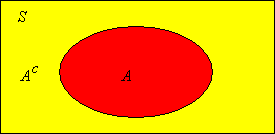
\(\P(A^c) = 1 - \P(A)\). This is the complement rule.
Note that \(A\) and \(A^c\) are disjoint and \(S = A \cup A^c\). Hence \(1 = \P(S) = \P(A) + \P(A^c)\).
\(\P(B \setminus A) = \P(B) - \P(A \cap B)\). This is the difference rule.
Note that \(A \cap B\) and \(B \setminus A\) are disjoint and \(B = (A \cap B) \cup (B \setminus A)\). Hence \(\P(B) = \P(A \cap B) + \P(B \setminus A)\).
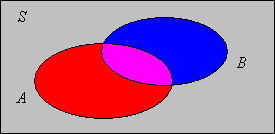
If \(A \subseteq B\) then \(\P(B \setminus A) = \P(B) - \P(A)\). This is the proper difference rule.
Recall that if \( A \subseteq B \) we sometimes write \( B - A \) for the set difference, rather than \( B \setminus A \). With this notation, the difference rule has the nice form \( \P(B - A) = \P(B) - \P(A) \).
If \(A \subseteq B\) then \(\P(A) \le \P(B)\).
So \(\P\) is an increasing function, relative to the subset partial order on the collection of events \( \ms S \), and the ordinary order on \(\R\). In particular, it follows that \(\P(A) \le 1\) for any event \(A\).
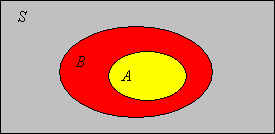
Suppose that \(A \subseteq B\).
An event \(A\) with \(\P(A) = 0\) is a null event while an event \(A\) with \(\P(A) = 1\) is an almost certain event (or an almost sure event).
The next result is known as Boole's inequality, named after George Boole. The inequality gives a simple upper bound on the probability of a union.
If \(\{A_i: i \in I\}\) is a countable collection of events then \[\P\left( \bigcup_{i \in I} A_i \right) \le \sum_{i \in I} \P(A_i)\]
Without loss of generality, we can assume that \(I = \{1, 2, \ldots\}\). Define \(B_1 = A_1\) and \(B_n = A_n \setminus \left(\bigcup_{i=1}^{n-1} A_i\right) \) for \(n \in \{2, 3, \ldots\}\). Note that \(\{B_1, B_2, \ldots\}\) is a pairwise disjoint collection of events and has the same union as \(\{A_1, A_2, \ldots\}\). Note also that \( B_i \subseteq A_i \) for each \( i \). Thus, from countable additivity in and the increasing property in , \[ \P\left(\bigcup_{i=1}^\infty A_i\right) = \P\left(\bigcup_{i=1}^\infty B_i\right) = \sum_{i=1}^\infty \P(B_i) \le \sum_{i=1}^\infty \P(A_i) \]
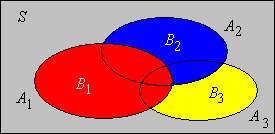
Intuitively, Boole's inequality holds because parts of the union have been measured more than once in the sum of the probabilities on the right. Of course, the sum of the probabilities may be greater than 1, in which case Boole's inequality is not helpful. The following result is a simple consequence of Boole's inequality .
If \(\{A_i: i \in I\}\) is a countable collection of events with \(\P(A_i) = 0\) for each \(i \in I\), then \[\P\left( \bigcup_{i \in I} A_i \right) = 0\]
So a countable union of null events is still a null event. The next result is known as Bonferroni's inequality, named after Carlo Bonferroni. The inequality gives a simple lower bound for the probability of an intersection.
If \(\{A_i: i \in I\}\) is a countable collection of events then \[\P\left( \bigcap_{i \in I} A_i \right) \ge 1 - \sum_{i \in I}\left[1 - \P(A_i)\right]\]
By De Morgan's law, \( \left(\bigcap_{i \in I} A_i\right)^c = \bigcup_{i \in I} A_i^c \). Hence by Boole's inequality and the complement rule , \[ \P\left[\left(\bigcap_{i \in I} A_i\right)^c\right] = \P\left(\bigcup_{i \in I} A_i^x\right) \le \sum_{i \in I} \P(A_i^c) = \sum_{i \in I} \left[1 - \P(A_i)\right] \] Using the complement rule again gives Bonferroni's inequality.
Of course, the lower bound in Bonferroni's inequality may be less than or equal to 0, in which case it's not helpful. The following result is a simple consequence of Bonferroni's inequality.
If \(\{A_i: i \in I\}\) is a countable collection of events with \(\P(A_i) = 1\) for each \(i \in I\), then \[\P\left( \bigcap_{i \in I} A_i \right) = 1\]
So a countable intersection of almost sure events is still almost sure.
Suppose that \(A\) and \(B\) are evemts.
Suppose that \(\{A_i: i \in I\}\) is a countable collection of events that partition \(S\). Recall that this means that the events are disjoint and their union is \(S\). For any event \(B\), \[\P(B) = \sum_{i \in I} \P(A_i \cap B)\]
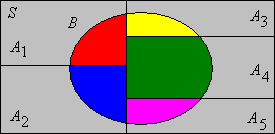
Naturally, this result is useful when the probabilities of the intersections are known. Partitions usually arise in connection with a random variable. Suppose that \(X\) is a random variable in a countable set \(S\), and that \(B\) is an event. Then \[\P(B) = \sum_{x \in S} \P(X = x, B)\] In this formula, note that the comma acts like the intersection symbol in .
The inclusion-exclusion formulas provide a method for computing the probability of a union of events in terms of the probabilities of the various intersections of the events. The formula is useful because often the probabilities of the intersections are easier to compute. Interestingly, however, the same formula works for computing the probability of an intersection of events in terms of the probabilities of the various unions of the events. This version is rarely stated, because it's simply not that useful. We start with two events.
If \( A, \, B \) are events thatn \(\P(A \cup B) = \P(A) + \P(B) - \P(A \cap B)\).
Here is the complementary result for the intersection in terms of unions:
If \( A, \, B \) are events then \(\P(A \cap B) = \P(A) + \P(B) - \P(A \cup B)\).
This follows immediately from the previous formula be rearranging the terms
Next we consider three events.
If \( A, \, B, \, C \) are events then \(\P(A \cup B \cup C) = \P(A) + \P(B) + \P(C) - \P(A \cap B) - \P(A \cap C) - \P(B \cap C) + \P(A \cap B \cap C)\).
Analytic Proof: First note that \( A \cup B \cup C = (A \cup B) \cup [C \setminus (A \cup B)] \). The event in parentheses and the event in square brackets are disjoint. Thus, using the additivity axiom and the difference rule, \[ \P(A \cup B \cup C) = \P(A \cup B) + \P(C) - \P\left[C \cap (A \cup B)\right] = \P(A \cup B) + \P(C) - \P\left[(C \cap A) \cup (C \cap B)\right] \] Using the inclusion-exclusion rule for two events (twice) we have \[ \P(A \cup B \cup C) = \P(A) + \P(B) - \P(A \cap B) + \P(C) - \left[\P(C \cap A) + \P(C \cap B) - \P(A \cap B \cap C)\right] \]
Proof by accounting: Note that \( A \cup B \cup C \) is the union of the seven disjoint, colored events in the picture below (not counting the gray event, which is the complement of the uniion). We will argue that each of these events is measured precisely once in the inclusion-exclusion formula.
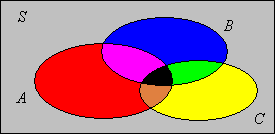
Here is the complementary result for the probability of an intersection in terms of the probabilities of the unions:
If \( A, \, B, \, C \) are events then \(\P(A \cap B \cap C) = \P(A) + \P(B) + \P(C) - \P(A \cup B) - \P(A \cup C) - \P(B \cup C) + \P(A \cup B \cup C)\).
The inclusion-exclusion formulas for two and three events can be generalized to \(n \in \N_+\) events. For the remainder of this discussion, suppose that \( \{A_i: i \in I\} \) is a collection of events where \( I \) is an index set with \( \#(I) = n \in \N_+ \).
The general inclusion-exclusion formula for the probability of a union. \[\P\left( \bigcup_{i \in I} A_i \right) = \sum_{k = 1}^n (-1)^{k - 1} \sum_{J \subseteq I, \; \#(J) = k} \P\left( \bigcap_{j \in J} A_j \right)\]
Analytic proof: This proof is by induction on \(n\). We have already established the formula for \( n = 2 \) in and \( n = 3 \) in . Thus, suppose that the inclusion-exclusion formula holds for a given \( n \in \N_+ \), and suppose that \( (A_1, A_2, \ldots, A_{n+1}) \) is a sequence of \( n + 1 \) events. Then \[ \bigcup_{i=1}^{n + 1} A_i = \left(\bigcup_{i=1}^n A_i \right) \cup \left[ A_{n+1} \setminus \left(\bigcup_{i=1}^n A_i\right) \right] \] As before, the event in parentheses and the event in square brackets are disjoint. Thus using the additivity axiom , the difference rule , and the distributive rule from set theory we have \[ \P\left(\bigcup_{i=1}^{n+1} A_i\right) = \P\left(\bigcup_{i=1}^n A_i\right) + \P(A_{n+1}) - \P\left(\bigcup_{i=1}^n (A_{n+1} \cap A_i) \right) \] By the induction hypothesis, the inclusion-exclusion formula holds for each union of \( n \) events on the right. Applying the formula and simplifying gives the inclusion-exclusion formula for \( n + 1 \) events.
Proof by accounting: This proof is the general version of the same argument we used for 3 events in . \( \bigcup_{i \in I} A_i \) is the union of the disjoint events of the form \( \left(\bigcap_{i \in K} A_i\right) \cap \left(\bigcap_{i \in K^c} A_i\right)\) where \( K \) is a nonempty subset of the index set \( I \). In the inclusion-exclusion formula, the event corresponding to a given \( K \) is measured in \( \P\left(\bigcap_{j \in J} A_j\right) \) for every nonempty \( J \subseteq K \). Suppose that \( \#(K) = k \). Accounting for the positive and negative signs, the net measurement is \( \sum_{j = 1}^k (-1)^{j-1} \binom{k}{j} = 1 \).
Here is the complementary result for the probability of an intersection in terms of the probabilities of the various unions:
The general inclusion-exclusion formula for the probability of an intersection. \[\P\left( \bigcap_{i \in I} A_i \right) = \sum_{k = 1}^n (-1)^{k - 1} \sum_{J \subseteq I, \; \#(J) = k} \P\left( \bigcup_{j \in J} A_j \right)\]
The general inclusion-exclusion formulas are not worth remembering in detail, but only in pattern. For the probability of a union, we start with the sum of the probabilities of the events, then subtract the probabilities of all of the paired intersections, then add the probabilities of the third-order intersections, and so forth, alternating signs, until we get to the probability of the intersection of all of the events.
The general Bonferroni inequalities (for a union) state that if sum on the right in is truncated, then the truncated sum is an upper bound or a lower bound for the probability on the left, depending on whether the last term has a positive or negative sign. Here is the result stated explicitly:
Suppose that \( m \in \{1, 2, \ldots, n - 1\} \). Then
Let \( P_k = \sum_{J \subseteq I, \; \#(J) = k} \P\left( \bigcap_{j \in J} A_j \right) \), the absolute value of the \( k \)th term in the inclusion-exclusion formula. The result follows since the inclusion-exclusion formula is an alternating series, and \( P_k \) is decreasing in \( k \).
More elegant proofs of the inclusion-exclusion formula and the Bonferroni inequalities can be constructed using expected value.
Note that there is a probability term in the inclusion-exclusion formulas for every nonempty subset \( J \) of the index set \( I \), with either a positive or negative sign, and hence there are \( 2^n - 1 \) such terms. These probabilities suffice to compute the probability of any event that can be constructed from the given events, not just the union or the intersection.
The probability of any event that can be constructed from \( \{A_i: i \in I\} \) can be computed from either of the following collections of \( 2^n - 1 \) probabilities:
If you go back and look at the proofs of the rules of probability, you will see that they hold for any finite measure \(\mu\), not just probability. The only change is that the number 1 is replaced by \(\mu(S)\). In particular, the inclusion-exclusion rule is as important in combinatorics (the study of counting measure) as it is in probability.
Suppose that \(A\) and \(B\) are events in an experiment with \(\P(A) = \frac{1}{3}\), \(\P(B) = \frac{1}{4}\), \(\P(A \cap B) = \frac{1}{10}\). Express each of the following events in the language of the experiment and find its probability:
Suppose that \(A\), \(B\), and \(C\) are events in an experiment with \(\P(A) = 0.3\), \(\P(B) = 0.2\), \(\P(C) = 0.4\), \(\P(A \cap B) = 0.04\), \(\P(A \cap C) = 0.1\), \(\P(B \cap C) = 0.1\), \(\P(A \cap B \cap C) = 0.01\). Express each of the following events in set notation and find its probability:
Suppose that \(A\) and \(B\) are events in an experiment with \(\P(A \setminus B) = \frac{1}{6}\), \(\P(B \setminus A) = \frac{1}{4}\), and \(\P(A \cap B) = \frac{1}{12}\). Find the probability of each of the following events:
Suppose that \(A\) and \(B\) are events in an experiment with \(\P(A) = \frac{2}{5}\), \(\P(A \cup B) = \frac{7}{10}\), and \(\P(A \cap B) = \frac{1}{6}\). Find the probability of each of the following events:
Suppose that \(A\), \(B\), and \(C\) are events in an experiment with \(\P(A) = \frac{1}{3}\), \(\P(B) = \frac{1}{4}\), \(\P(C) = \frac{1}{5}\).
Open the simple probability experiment.
Suppose that \(A\), \(B\), and \(C\) are events in a random experiment with \( \P(A) = 1/4 \), \( \P(B) = 1/3 \), \( \P(C) = 1/6 \), \( \P(A \cap B) = 1/18 \), \( \P(A \cap C) = 1/16 \), \( \P(B \cap C) = 1/12 \), and \( \P(A \cap B \cap C) = 1/24 \). Find the probabilities of the various unions:
Suppose that \(A\), \(B\), and \(C \) are events in a random experiment with \( \P(A) = 1/4 \), \( \P(B) = 1/4 \), \( \P(C) = 5/16 \), \( \P(A \cup B) = 7/16 \), \( \P(A \cup C) = 23/48 \), \( \P(B \cup C) = 11/24 \), and \( \P(A \cup B \cup C) = 7/12 \). Find the probabilities of the various intersections:
Suppose that \(A\), \(B\), and \(C\) are events in a random experiment. Explicitly give all of the Bonferroni inequalities for \( \P(A \cup B \cup C) \)
Consider the random experiment of tossing a coin \(n\) times and recording the sequence of scores \(\bs{X} = (X_1, X_2, \ldots, X_n)\) (where 1 denotes heads and 0 denotes tails). This experiment is a generic example of \(n\) Bernoulli trials, named for Jacob Bernoulli. Note that the set of outcomes is \(S = \{0, 1\}^n\), the set of bit strings of length \(n\). If the coin is fair, then presumably, by the very meaning of the word, we have no reason to prefer one point in \(S\) over another. So as a modeling assumption, it seems reasonable to give \(S\) the uniform probability distribution , in which all outcomes are equally likely.
Suppose that a fair coin is tossed 3 times and the sequence of coin scores is recorded. Let \(A\) be the event that the first coin is heads and \(B\) the event that there are exactly 2 heads. Give each of the following events in list form, and then compute the probability of the event:
In the Coin experiment, select 3 coins. Run the experiment 1000 times, updating after every run, and compute the empirical probability of each event in exercise .
Suppose that a fair coin is tossed 4 times and the sequence of scores is recorded. Let \(Y\) denote the number of heads. Give the event \(\{Y = k\}\) (as a subset of the sample space) in list form, for each \(k \in \{0, 1, 2, 3, 4\}\), and then give the probability of the event.
Suppose that a fair coin is tossed \(n\) times and the sequence of scores is recorded. Let \(Y\) denote the number of heads. \[\P(Y = k) = \binom{n}{k} \left( \frac{1}{2} \right)^n, \quad k \in \{0, 1, \ldots, n\}\]
The number of bit strings of length \(n\) is \(2^n\), and since the coin is fair, these are equally likely. The number of bit strings of length \(n\) with exactly \(k\) 1's is \(\binom{n}{k}\). Hence the probability of 1 occurring exactly \(k\) times is \(\binom{n}{k} \big/ 2^n\).
The distribution of \(Y\) in is a special case of the binomial distribution.
Consider the experiment of throwing \(n\) distinct, \(k\)-sided dice (with faces numbered from 1 to \(k\)) and recording the sequence of scores \(\bs{X} = (X_1, X_2, \ldots, X_n)\). We can record the outcome as a sequence because of the assumption that the dice are distinct; you can think of the dice as somehow labeled from 1 to \(n\), or perhaps with different colors. The special case \(k = 6\) corresponds to standard dice. In general, note that the set of outcomes is \(S = \{1, 2, \ldots, k\}^n\). If the dice are fair, then again, by the very meaning of the word, we have no reason to prefer one point in \( S \) over another, so as a modeling assumption it seems reasonable to give \(S\) the uniform probability distribution in .
Suppose that two fair, standard dice are thrown and the sequence of scores recorded. Let \(A\) denote the event that the first die score is less than 3 and \(B\) the event that the sum of the dice scores is 6. Give each of the following events in list form and then find the probability of the event.
In the dice experiment, set \(n = 2\). Run the experiment 100 times and compute the empirical probability of each event in exercise .
Consider again the dice experiment with \(n = 2\) fair dice. Let \( S \) denote the set of outcomes, \(Y\) the sum of the scores, \(U\) the minimum score, and \(V\) the maximum score.
Note that \( S = \{1, 2, 3, 4, 5, 6\}^2 \).
| \(y\) | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| \(\P(Y = y)\) | \(\frac{1}{36}\) | \(\frac{2}{36}\) | \(\frac{3}{36}\) | \(\frac{4}{36}\) | \(\frac{5}{36}\) | \(\frac{6}{36}\) | \(\frac{5}{36}\) | \(\frac{4}{36}\) | \(\frac{3}{36}\) | \(\frac{2}{36}\) | \(\frac{1}{36}\) |
| \(u\) | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| \(\P(U = u)\) | \(\frac{11}{36}\) | \(\frac{9}{36}\) | \(\frac{7}{36}\) | \(\frac{5}{36}\) | \(\frac{3}{36}\) | \(\frac{1}{36}\) |
| \(v\) | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| \(\P(V = v)\) | \(\frac{1}{36}\) | \(\frac{3}{36}\) | \(\frac{5}{36}\) | \(\frac{6}{36}\) | \(\frac{7}{36}\) | \(\frac{11}{36}\) |
In exercise , note that \((U, V)\) could serve as the outcome vector for the experiment of rolling two standard, fair dice if we do not bother to distinguish the dice (so that we might as well record the smaller score first and then the larger score). Note that this random vector does not have a uniform distribution. On the other hand, we might have chosen at the beginning to just record the unordered set of scores and, as a modeling assumption, imposed the uniform distribution on the corresponding set of outcomes. Both models cannot be right, so which model (if either) describes real dice in the real world? It turns out that for real (fair) dice, the ordered sequence of scores is uniformly distributed, so real dice behave as distinct objects, whether you can tell them apart or not. In the early history of probability, gamblers sometimes got the wrong answers for events involving dice because they mistakenly applied the uniform distribution to the set of unordered scores. It's an important moral. If we are to impose the uniform distribution on a sample space, we need to make sure that it's the right sample space.
A pair of fair, standard dice are thrown repeatedly until the sum of the scores is either 5 or 7. Let \(A\) denote the event that the sum of the scores on the last throw is 5 rather than 7.
Let \(D_5 = \{(1,4), (2,3), (3,2), (4,1)\}\), \(D_7 = \{(1,6), (2,5), (3,4), (4,3), (5,2), (6,1)\}\), \(D = D_5 \cup D_7\), \(C = \{1, 2, 3, 4, 5, 6\}^2 \setminus D\)
Exercise shows the importance of defining the set of outcomes appropriately. Sometimes a clever choice of this set (and appropriate modeling assumptions) can turn a difficult problem into an easy one. Events of the type in this exercise are important in the game of craps
Recall that many random experiments can be thought of as sampling experiments. For the general finite sampling model, we start with a population \(D\) with \(m\) (distinct) objects. We select a sample of \(n\) objects from the population, so that the sample space \(S\) is the set of possible samples. If we select a sample at random then the outcome \(\bs{X}\) (the random sample) is uniformly distributed on \(S\): \[\P(\bs{X} \in A) = \frac{\#(A)}{\#(S)}, \quad A \subseteq S\]
Recall fthat there are four common types of sampling from a finite population, based on the criteria of order and replacement.
If we sample with replacement, the sample size \(n\) can be any positive integer. If we sample without replacement, the sample size cannot exceed the population size, so we must have \(n \in \{1, 2, \ldots, m\}\).
The basic coin and dice experiments are examples of sampling with replacement. If we toss a fair coin \(n\) times and record the sequence of scores \(\bs{X}\) (where as usual, 0 denotes tails and 1 denotes heads), then \(\bs{X}\) is a random sample of size \(n\) chosen with order and with replacement from the population \(\{0, 1\}\). Thus, \(\bs{X}\) is uniformly distributed on \(\{0, 1\}^n\). If we throw \(n\) (distinct) standard fair dice and record the sequence of scores, then we generate a random sample \(\bs{X}\) of size \(n\) with order and with replacement from the population \(\{1, 2, 3, 4, 5, 6\}\). Thus, \(\bs{X}\) is uniformly distributed on \(\{1, 2, 3, 4, 5, 6\}^n\). Of an analogous result would hold for fair, \(k\)-sided dice.
Suppose that the sampling is without replacement (the most common case). If we record the ordered sample \(\bs{X} = (X_1, X_2, \ldots, X_n)\), then the unordered sample \(\bs{W} = \{X_1, X_2, \ldots\}\) is a random variable (that is, a function of \(\bs{X}\)). On the other hand, if we just record the unordered sample \(\bs{W}\) in the first place, then we cannot recover the ordered sample.
Suppose that \(\bs{X}\) is a random sample of size \(n\) chosen with order and without replacement from \(D\), so that \(\bs{X}\) is uniformly distributed on the space of permutations of size \(n\) from \(D\). Then \(\bs{W}\), the unordered sample, is uniformly distributed on the space of combinations of size \(n\) from \(D\). Thus, \(\bs{W}\) is also a random sample.
Let \(\bs{w}\) be a combination of size \(n\) from \(D\). Then there are \(n!\) permutations of the elements in \(\bs{w}\). If \(A\) denotes this set of permutations, then \(\P(\bs{W} = \bs{w}) = \P(\bs{X} \in A) = n! \big/ m^{(n)} = 1 \big/ \binom{m}{n}\).
Theorem does not hold if the sampling is with replacement (recall the discussion after exercise ). When sampling with replacement, there is no simple relationship between the number of ordered samples and the number of unordered samples.
Suppose again that we have a population \(D\) with \(m \in \N_+\) (distinct) objects, but suppose now that each object is one of two types—either type 1 or type 0. Such populations are said to be dichotomous.
Typical examples of dichotomous populations:
Suppose that the population \(D\) has \(r\) type 1 objects and hence \(m - r\) type 0 objects. Of course, we must have \(r \in \{0, 1, \ldots, m\}\). Now suppose that we select a sample of size \(n\) at random from the population. Note that this model has three parameters: the population size \(m\), the number of type 1 objects in the population \(r\), and the sample size \(n\). Let \(Y\) denote the number of type 1 objects in the sample.
Suppose that the sampling is without replacement so that \(n \in \{0, 1, \ldots, m\}\). Then \[\P(Y = y) = \frac{\binom{r}{y} \binom{m - r}{n - y}}{\binom{m}{n}}, \quad y \in \{0, 1, \ldots, n\}\]
Recall that the unordered sample is uniformly distributed over the set of combinations of size \(n\) chosen from the population. There are \(\binom{m}{n}\) such samples. By the multiplication principle, the number of samples with exactly \(y\) type 1 objects and \(n - y\) type 0 objects is \(\binom{r}{y} \binom{m - r}{n - y}\).
In , random variable \(Y\) has the hypergeometric distribution with parameters \(m\), \(r\), and \(n\).
Suppose the sampling is with replacement so that \(n \in \N_+\). Then \[\P(Y = y) = \binom{n}{y} \frac{r^y (m - r)^{n-y}}{m^n} = \binom{n}{y} \left( \frac{r}{m}\right)^y \left( 1 - \frac{r}{m} \right)^{n - y}, \quad y \in \{0, 1, \ldots, n\}\]
Recall that the ordered sample is uniformly distributed over the set \(D^n\) and there are \(m^n\) elements in this set. To count the number of samples with exactly \(y\) type 1 objects, we use a three-step procedure: first, select the coordinates for the type 1 objects; there are \(\binom{n}{y}\) choices. Next select the \(y\) type 1 objects for these coordinates; there are \(r^y\) choices. Finally select the \(n - y\) type 0 objects for the remaining coordinates of the sample; there are \((m - r)^{n - y}\) choices. The result now follows from the multiplication principle.
In , random variable \(Y\) has the binomial distribution with parameters \(n\) and \(p = \frac{r}{m}\).
Suppose that a group of voters consists of 40 democrats and 30 republicans. A sample 10 voters is chosen at random. Find the probability that the sample contains at least 4 democrats and at least 4 republicans, each of the following cases:
Look for other specialized sampling situations in the exercises below.
Drawing balls from an urn is a standard metaphor in probability for sampling from a finite population.
Consider an urn with 30 balls; 10 are red and 20 are green. A sample of 5 balls is chosen at random, without replacement. Let \(Y\) denote the number of red balls in the sample. Explicitly compute \(\P(Y = y)\) for each \(y \in \{0, 1, 2, 3, 4, 5\}\).
| \(y\) | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| \(\P(Y = y)\) | \(\frac{2584}{23751}\) | \(\frac{8075}{23751}\) | \(\frac{8550}{23751}\) | \(\frac{3800}{23751}\) | \(\frac{700}{23751/}\) | \(\frac{42}{23751}\) |
In the simulation of the ball and urn experiment, select 30 balls with 10 red and 20 green, sample size 5, and sampling without replacement. Run the experiment 1000 times and compare the empirical probabilities with the true probabilities that you computed in exercise .
Consider again an urn with 30 balls; 10 are red and 20 are green. A sample of 5 balls is chosen at random, with replacement. Let \(Y\) denote the number of red balls in the sample. Explicitly compute \(\P(Y = y)\) for each \(y \in \{0, 1, 2, 3, 4, 5\}\).
| \(y\) | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| \(\P(Y = y)\) | \(\frac{32}{243}\) | \(\frac{80}{243}\) | \(\frac{80}{243}\) | \(\frac{40}{243}\) | \(\frac{10}{243}\) | \(\frac{1}{243}\) |
In the simulation of the ball and urn experiment, select 30 balls with 10 red and 20 green, sample size 5, and sampling with replacement. Run the experiment 1000 times and compare the empirical probabilities with the true probabilities that you computed in exercise .
An urn contains 15 balls: 6 are red, 5 are green, and 4 are blue. Three balls are chosen at random, without replacement.
Suppose again that an urn contains 15 balls: 6 are red, 5 are green, and 4 are blue. Three balls are chosen at random, with replacement.
Recall that a standard card deck can be modeled by the product set \[D = \{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, j, q, k\} \times \{\clubsuit, \diamondsuit, \heartsuit, \spadesuit\}\] where the first coordinate encodes the denomination or kind (ace, 2–10, jack, queen, king) and where the second coordinate encodes the suit (clubs, diamonds, hearts, spades). Sometimes we represent a card as a string rather than an ordered pair (for example \(q \heartsuit\) for the queen of hearts).
Card games involve choosing a random sample without replacement from the deck \(D\), which plays the role of the population, as in . Thus, the basic card experiment consists of dealing \(n\) cards from a standard deck without replacement; in this special context, the sample of cards is often referred to as a hand. Just as in the general sampling model, if we record the ordered hand \(\bs{X} = (X_1, X_2, \ldots, X_n)\), then the unordered hand \(\bs{W} = \{X_1, X_2, \ldots, X_n\}\) is a random variable (that is, a function of \(\bs{X}\)). On the other hand, if we just record the unordered hand \(\bs{W}\) in the first place, then we cannot recover the ordered hand. Finally, recall that \(n = 5\) is the poker experiment and \(n = 13\) is the bridge experiment. By the way, it takes about 7 standard riffle shuffles to randomize a deck of cards.
Suppose that 2 cards are dealt from a well-shuffled deck and the sequence of cards is recorded. For \(i \in \{1, 2\}\), let \(H_i\) denote the event that card \(i\) is a heart. Find the probability of each of the following events.
Think about the results in exercise , and suppose that we continue dealing cards. Note that in computing the probability of \(H_i\), you could conceptually reduce the experiment to dealing a single card. Note also that the probabilities do not depend on the order in which the cards are dealt. For example, the probability of an event involving the 1st, 2nd and 3rd cards is the same as the probability of the corresponding event involving the 25th, 17th, and 40th cards. Technically, the cards are exchangeable. Here's another way to think of this concept: Suppose that the cards are dealt onto a table in some pattern, but you are not allowed to view the process. Then no experiment that you can devise will give you any information about the order in which the cards were dealt.
In the card experiment, set \(n = 2\). Run the experiment 100 times and compute the empirical probability of each event in exercise .
In the poker experiment, find the probability of each of the following events:
Run the poker experiment 10000 times, updating every 10 runs. Compute the empirical probability of each event in exercise .
Find the probability that a bridge hand will contain no cards of denomination 10, jack, queen, king, or ace. Such a hand is called a Yarborough, in honor of the second Earl of Yarborough.
\(\frac{347\,373\,600}{635\,013\,559\,600} \approx 0.000547\)
Find the probability that a bridge hand will contain
A card hand that contains no cards in a particular suit is said to be void in that suit. Use the inclusion-exclusion rule to find the probability of each of the following events:
The following problem is known as the birthday problem, and is famous because the results are rather surprising at first.
Suppose that \(n\) persons are selected and their birthdays recorded (we will ignore leap years). Let \(A\) denote the event that the birthdays are distinct, so that \(A^c\) is the event that there is at least one duplication in the birthdays.
| \(n\) | \(\P(A)\) | \(\P(A^c)\) |
|---|---|---|
| 10 | 0.883 | 0.117 |
| 20 | 0.589 | 0.411 |
| 30 | 0.294 | 0.706 |
| 40 | 0.109 | 0.891 |
| 50 | 0.006 | 0.994 |
The small value of \(\P(A)\) for relatively small sample sizes \(n\) is striking, but is due mathematically to the fact that \(365^n\) grows much faster than \(365^{(n)}\) as \(n\) increases.
Suppose that 4 persons are selected and their birth months recorded. Assuming an appropriate uniform distribution, find the probability that the months are distinct.
\(\frac{11880}{20736} \approx 0.573\)
Details:
Recall that in Buffon's coin experiment, a coin with radius \(r \le \frac{1}{2}\) is tossed randomly
on a floor with square tiles of side length 1, and the coordinates \((X, Y)\) of the center of the coin are recorded, relative to axes through the center of the square in which the coin lands (with the axes parallel to the sides of the square, of course). Let \(A\) denote the event that the coin does not touch the sides of the square.
randomly, no region of \(S\) should be preferred over any other.
In Buffon's coin experiment, set \(r = 0.2\). Run the experiment 100 times and compute the empirical probability of each event in exercise .
A point \((X, Y)\) is chosen at random in the circular region \(S \subset \R^2\) of radius 1, centered at the origin. Let \(A\) denote the event that the point is in the inscribed square region centered at the origin, with sides parallel to the coordinate axes, and let \(B\) denote the event that the point is in the inscribed square with vertices \((\pm 1, 0)\), \((0, \pm 1)\). Sketch each of the following events as a subset of \(S\), and find the probability of the event.
Suppose a point \((X, Y)\) is chosen at random in the circular region \(S \subseteq \R^2\) of radius 12, centered at the origin. Let \(R\) denote the distance from the origin to the point. Sketch each of the following events as a subset of \(S\), and compute the probability of the event. Is \(R\) uniformly distributed on the interval \([0, 12]\)?
No, \(R\) is not uniformly distributed on \([0, 12]\).
In the simple probability experiment, points are generated according to the uniform distribution on a rectangle. Move and resize the events \( A \) and \( B \) and note how the probabilities of the various events change. Create each of the following configurations. In each case, run the experiment 1000 times and compare the relative frequencies of the events to the probabilities of the events.
Please refer to the previous discussion of genetics if you need to review some of the definitions in this subsection.
Recall first that the ABO blood type in humans is determined by three alleles: \(a\), \(b\), and \(o\). Furthermore, \(a\) and \(b\) are co-dominant and \(o\) is recessive. Suppose that the probability distribution for the set of blood genotypes in a certain population is given in the following table:
| Genotype | \(aa\) | \(ab\) | \(ao\) | \(bb\) | \(bo\) | \(oo\) |
|---|---|---|---|---|---|---|
| Probability | 0.050 | 0.038 | 0.310 | 0.007 | 0.116 | 0.479 |
A person is chosen at random from the population. Let \(A\), \(B\), \(AB\), and \(O\) be the events that the person is type \(A\), type \(B\), type \(AB\), and type \(O\) respectively. Let \(H\) be the event that the person is homozygous and \(D\) the event that the person has an \(o\) allele. Find the probability of the following events:
Suppose next that pod color in certain type of pea plant is determined by a gene with two alleles: \(g\) for green and \(y\) for yellow, and that \(g\) is dominant.
Let \(G\) be the event that a child plant has green pods. Find \(\P(G)\) in each of the following cases:
Next consider a sex-linked hereditary disorder in humans (such as colorblindness or hemophilia). Let \(h\) denote the healthy allele and \(d\) the defective allele for the gene linked to the disorder. Recall that \(d\) is recessive for women.
Let \(B\) be the event that a son has the disorder, \(C\) the event that a daughter is a healthy carrier, and \(D\) the event that a daughter has the disease. Find \(\P(B)\), \(\P(C)\) and \(\P(D)\) in each of the following cases:
From exercise , note that transmission of the disorder to a daughter can only occur if the mother is at least a carrier and the father has the disorder. In ordinary large populations, this is a unusual intersection of events, and thus sex-linked hereditary disorders are typically much less common in women than in men. In brief, women are protected by the extra X chromosome.
Suppose that \(T\) denotes the time between emissions (in milliseconds) for a certain type of radioactive material, and that \(T\) has the following probability distribution, defined for measurable \(A \subseteq [0, \infty)\) by \[\P(T \in A) = \int_A e^{-t} \, dt\]
Suppose that \(N\) denotes the number of emissions in a one millisecond interval for a certain type of radioactive material, and that \(N\) has the following probability distribution: \[\P(N \in A) = \sum_{n \in A} \frac{e^{-1}}{n!}, \quad A \subseteq \N\]
The probability distribution that governs the time between emissions in is a special case of the exponential distribution, while the probability distribution that governs the number of emissions in is a special case of the Poisson distribution, named for Simeon Poisson.
Suppose that at an absented-minded secretary prepares 4 letters and matching envelopes to send to 4 different persons, but then stuffs the letters into the envelopes randomly. Find the probability of the event \(A\) that at least one letter is in the proper envelope.
Note first that the set of outcomes \( S \) can be taken to be the set of permutations of \(\{1, 2, 3, 4\}\). For \(\bs{x} \in S\), \(x_i\) is the number of the envelope containing the \(i\)th letter. Clearly \(S\) should be given the uniform probability distribution. Next note that \(A = A_1 \cup A_2 \cup A_3 \cup A_4\) where \(A_i\) is the event that the \(i\)th letter is inserted into the \(i\)th envelope. Using the inclusion-exclusion rule gives \(\P(A) = \frac{5}{8}\).
Exercise is an example of the matching problem, originally formulated and studied by Pierre Remond Montmort. A complete analysis of the matching problem is given in the chapter on finite sampling models.
In the simulation of the matching experiment select \(n = 4\). Run the experiment 1000 times and compute the relative frequency of the event that at least one match occurs.
For the M&M data set, let \(R\) denote the event that a bag has at least 10 red candies, \(T\) the event that a bag has at least 57 candies total, and \(W\) the event that a bag weighs at least 50 grams. Find the empirical probability the following events:
For the cicada data, let \(W\) denote the event that a cicada weighs at least 0.20 grams, \(F\) the event that a cicada is female, and \(T\) the event that a cicada is type tredecula. Find the empirical probability of each of the following: